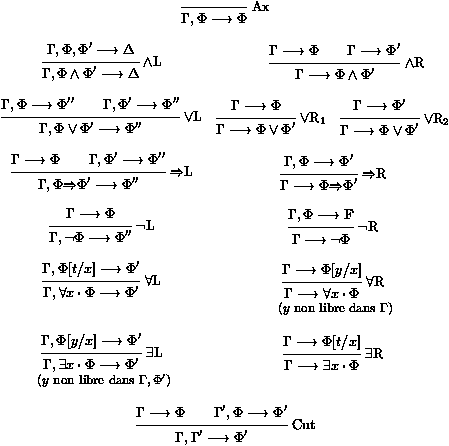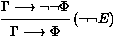
Et la sťmantique de Kripke de la logique intuitionniste est donnťe par un cadre (W,£), oý £ est un ordre (comme pour S4), un domaine non vide D, une interprťtation I des symboles de fonction et de prťdicats (oý I(P), pour chaque prťdicat P d'aritť m, est une fonction de Dm vers P W et non plus B), et oý pour toute affectation r :
Figure 4: Le systŤme LJ de Gentzen
Le cas de la logique linťaire est encore plus frappant. Alors que l'on connait plusieurs sťmantiques de la logique linťaire du premier ordre, aucune sťmantique n'a ťtť prouvťe complŤte---du moins, aucune sťmantique plus simple que le systŤme de preuves. La plupart des rťsultats en logique linťaire (la cohťrence, notamment) n'ont pu Ítre dťduits que par l'ťlimination des coupures et les propriťtťs des preuves par sťquents sans coupure.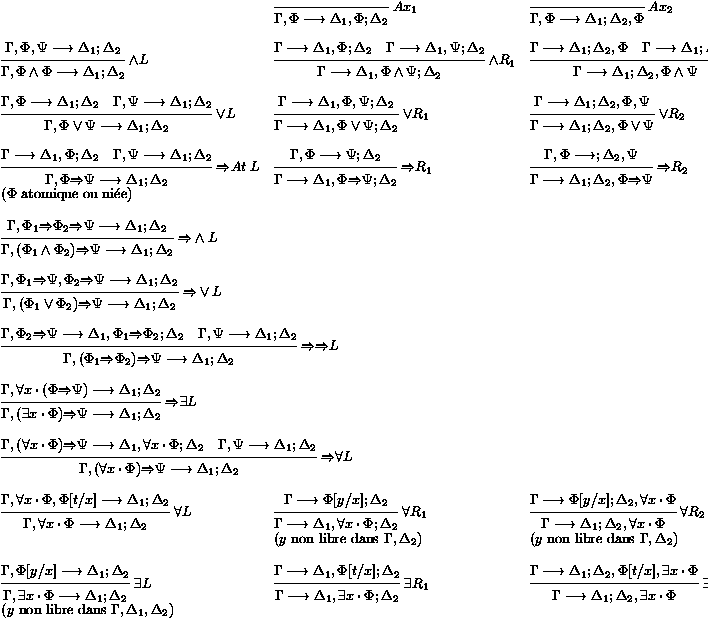
Figure 5: Le systŤme de Miglioli, Moscato et Ornaghi
| R f z 0 ģ z |
| R f z (s n) ģ f z n (R f z n) |
| " P |
|
∑ | P(0)Ŕ (" x |
|
∑ P(x)ř P(s(x)))ř | " x |
|
∑ P(x) |
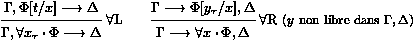
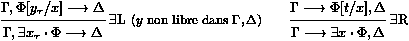
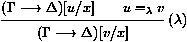
| ¨ $ F |
|
∑ | " P |
|
∑ | $ x |
|
∑ | " y |
|
∑ FxyŘ Py |
| " P |
|
∑ | (" x |
|
∑ | $ y |
|
∑ Pxy) ř | ($ f |
|
∑ | " x |
|
∑ Px(fx)) |
| " P |
|
∑ | P($ x |
|
∑F(x)) |
| $ x |
|
∑ F(x) |
| ¨$ x |
|
∑ F(x) |
| " F |
|
∑ | " G |
|
∑ (FŘ G)Ř F= G |